文章列表:
- 《Origin-Destination Flow Data Smoothing and Mapping》
- 《Stenomaps: Shorthand for Shapes》
- 《Nmap: A Novel Neighborhood Preservation Space-filling Algorithm》
- 《Tree Colors: Color Schemes for Tree-Structured Data》
《Origin-Destination Flow Data Smoothing and Mapping》
本文针对 Origin-Destination 流动数据的平滑和映射的三个明显问题:1. 流图的结果叠加造成了混乱;2.现有的聚类和分割方法会使提取出得 pattern 的准确性出现偏差;3.对于不在同一个数量级上得数据样本所得到的可是分析结果存在缺陷。提出了一种提取临界区域,基于核密度估计的流图聚类,筛选流线的方法,可以针对 Origin-Destination 类型的流畅数据,提取出用户所希望得到的结果。

本文的方法流程包括两个主要的步骤
a. 流图的核密度估计和平滑
b. 流图的生成
在第一个步骤中,文章提出的方法分为三个步骤:1.定义流图临界区域,以 P 的 Size 属性定义核心的位置和周边信息;2.定义流图核密度模型,定义 P 的 Value 属性值,可以归一化每个采样样本的数量级,利用高斯矩阵进行平滑处理;3.计算流图密度,通过前两步骤的条件,计算流图,达到 Smooth 的效果。
在第二个步骤中,文章对于已经平滑处理过的流线进行筛选和映射;同时,为了证明本文方法的实用性,文章介绍了该方法演化出的两种深层次的流图映射结果,分别是高分辨率的流图映射;分层次的流图映射图。
本文应用了两个具有说明性的 Evaluations 对本文的方法的结果进行讨论和验证。
- 利用美国各个地区净移民的数据,验证本文的方法论的结果,可以将开始时候杂乱无章的流图转化为最有代表性的效果图;其次,在局部地区以及根据属性的设定的分层次的流图结果,证明了方法的有效性。
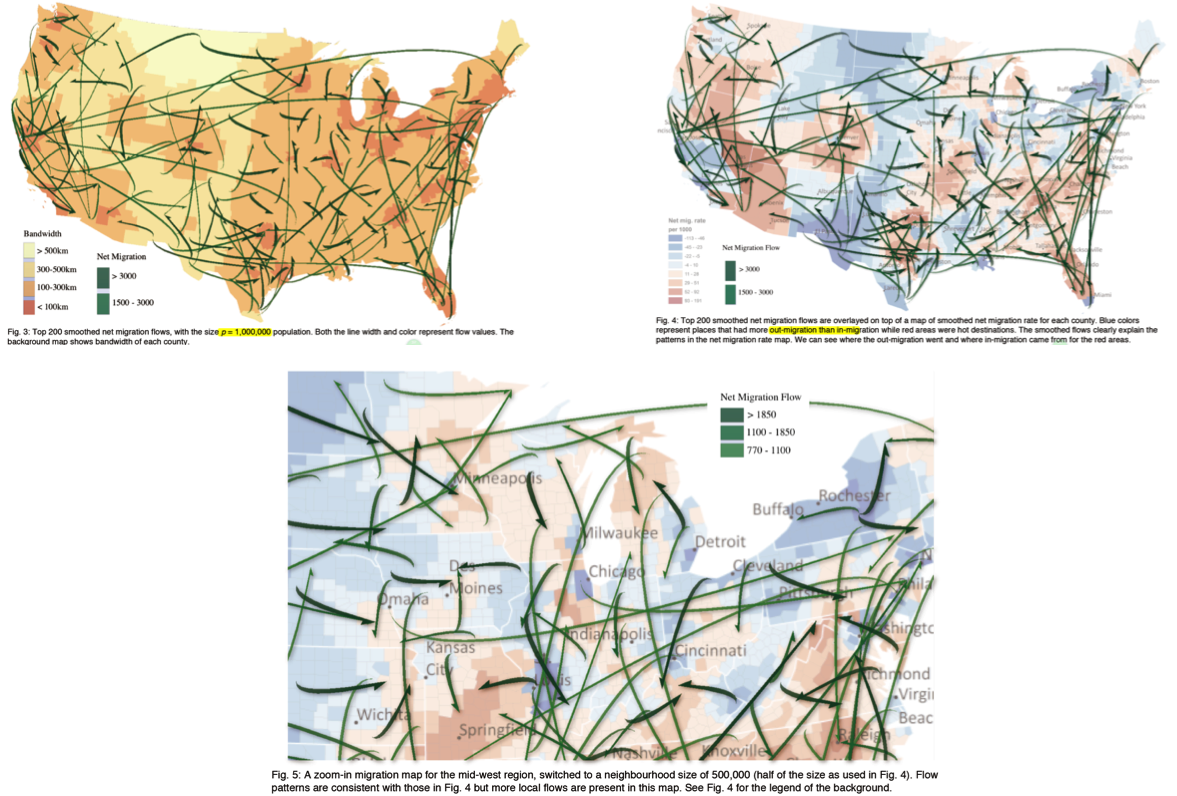
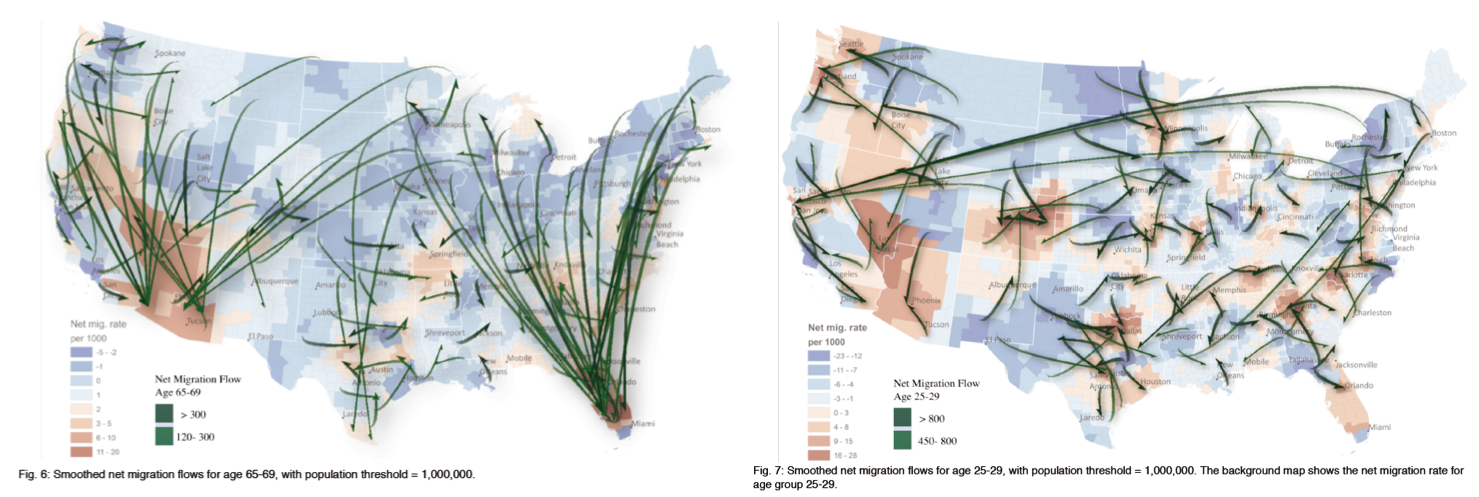
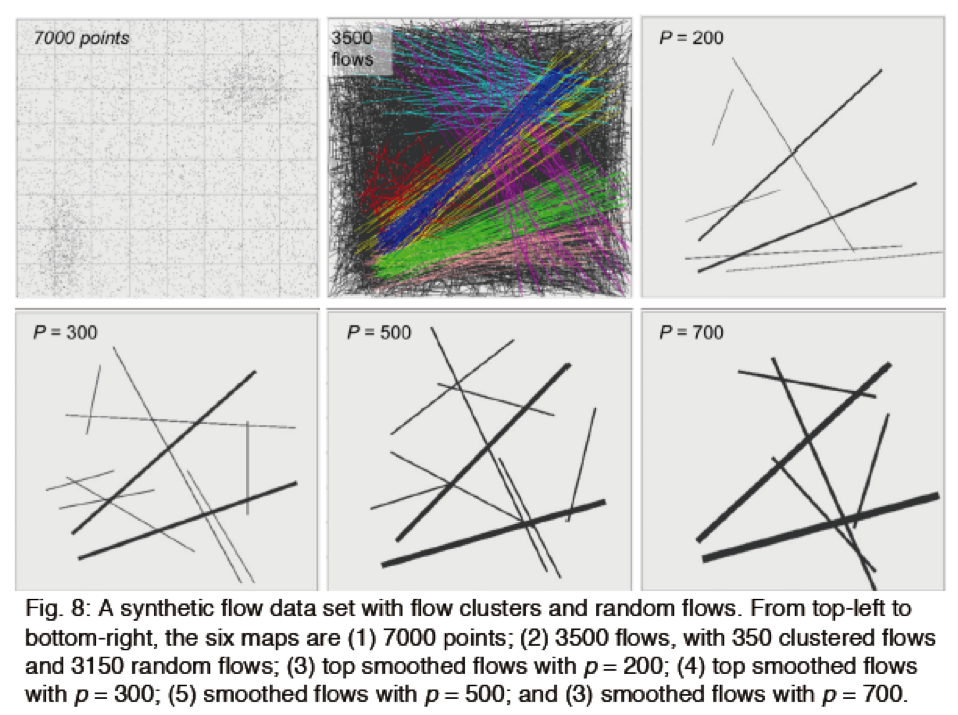
- 利用人造的流图数据,来验证在平滑流图的过程中所涉及的 P 值得参数的效果,即定义 P 值影响临界区域以及流图聚类的效果。
文章最后阐述了针对更大数量级(纽约出租车轨道数据),本文的方法难以承担如此大得数据集的映射。
《Stenomaps: Shorthand for Shapes》
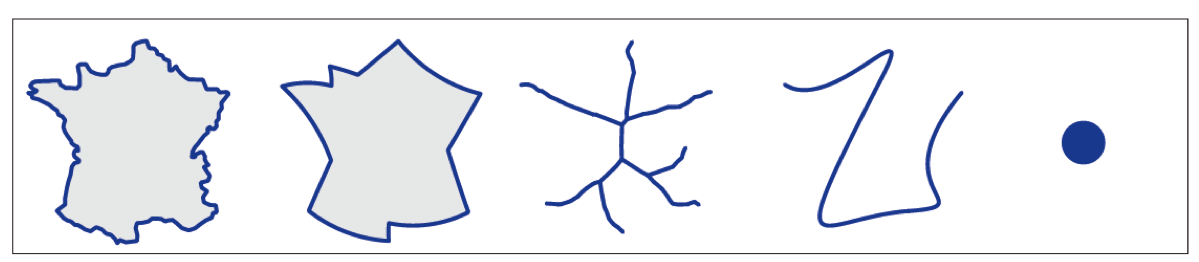
本文提出一种用线条简化形状,用一种缩略的 Glyph 表达形式,来减少人们的可视化的负担的方法。
本文的主要方法步骤为:
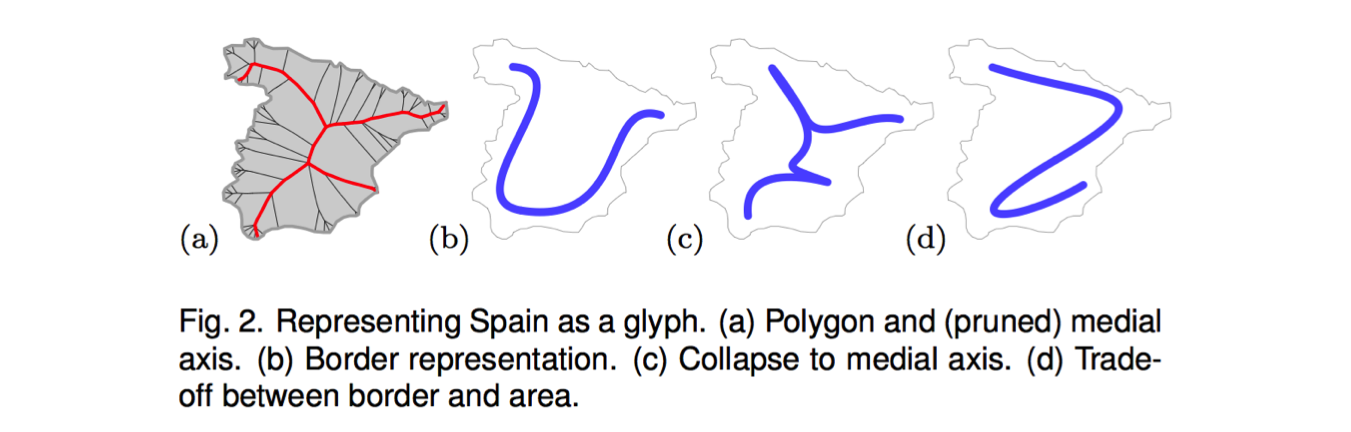
- 提取特征点
- 计算特征区域,避免产生不连续的特征区域
- 计算生成 Glyph 的特征区域方法:Path-Backbone; Tree-Backbone
- 生成 Glyph
Glyph 的种类主要分为三种:

- 简单形式的 Glyph
- 局部交叉的 Glyph
- 树形的 Glyph
Glyph 的应用:
- 通过编码 Glyph 的图案,结合其他的可视化数据,用 Glyph 表示地理空间信息,简化人们在可视化过程中对地理信息的信息表达,减少不必要的可视化输入。

- 通过美国飓风的影响范围数据,结合 Glyph 表示的地理区域,减少不确定性带来的视觉干扰。
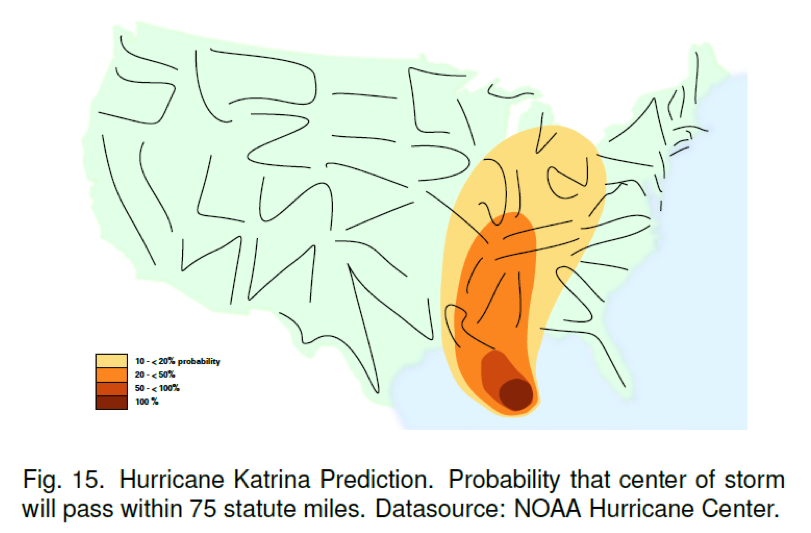
- Glyph 的表达形式,可以在连续的可视化数据的表现上,增强对连续性的观察性,不容易对数据的连续变化造成影响。

本文提出了一种 Glyph 的名为 Stenomaps 的可视化设计,在不需要精确的边界区分可以有效地帮助用户来理解形状的基本信息。通过简单地 Glyph 的表达形式,可以减少可视输入的复杂度,提供在高层次可视化更好的 overview 的效果。
《Nmap: A Novel Neighborhood Preservation Space-filling Algorithm》
本文提出了一种 TreeMap 的布局算法 Nmap,可以在 Treemap 的可视化结果更好的表达数据的相邻之间的关系。
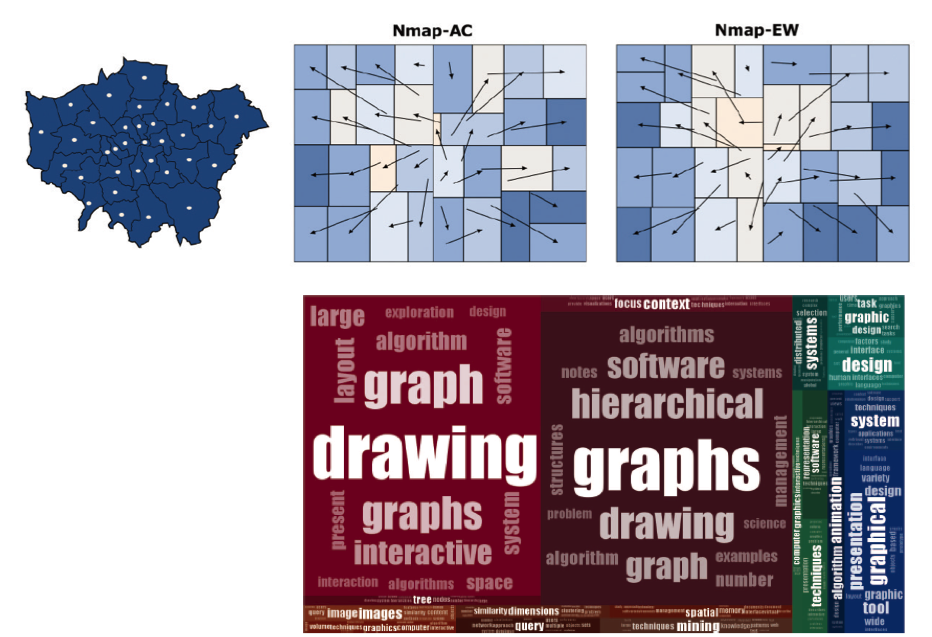
本文介绍了两种形式的 NMap 算法,分别是 NMap-AC 和 NMap-EW 两种,前者的切分方式是纵向分割和横向分割轮流的形式进行 TreeMap 的布局生成;后者则是实时根据节点矩形的长宽比例,优化切分的方向,可以使生成的 TreeMap 的每个方格的纵横比更加接近于 1,视觉效果更加理想。
文章根据如图的 9 种分布的数据,用 NMap 的两种方法,结合 OOT、SOT 两种传统的 TreeMap 的生成方法,对 9 种分布的数据集分别生成 TreeMap,对每种情况的 TreeMap 的纵横比、相对平移距离、相邻关系的保留情况三种方面进行对比。

通过图中的结果图,我们可以发现,本文提出的 NMap 算法,在这三个方面均优于传统的两种方法。并且随着数据数量级的增加,时间效率上本文的方法更加高效,保存的相对位置关系和位移情况得到了优化。

而文章通过表现文章的类别数据和城市的地图统计图生成 TreeMap,论证了本文的有效性。

《Tree Colors: Color Schemes for Tree-Structured Data》
本文提出了一种对于类别类型、分层数据的可视化方法的颜色配色方案。基于 Hue-Chroma-Luminance 的颜色属性模式,对于层次的类别性数据的可视化结果进行配色优化。
色相的取值范围为[0,360];亮度的取值范围为[0,100];饱和度的取值范围为[0,100]。通过调整色相、亮度和饱和度,本文提出了一种通过颜色编码具有层次结构的数据,结合 Node-link 图和 Treemap 图,防止在可视分析的过程中因为颜色编码造成的感官上的干扰。


色相:
- 通过排序和反转的处理更好的区别相邻节点的颜色;
- 色相的区间大小也可以影响节点的颜色差异大小。

亮度和饱和度:
表现数据的层次深度信息(Subtractive Color & Additive Color)
应用:
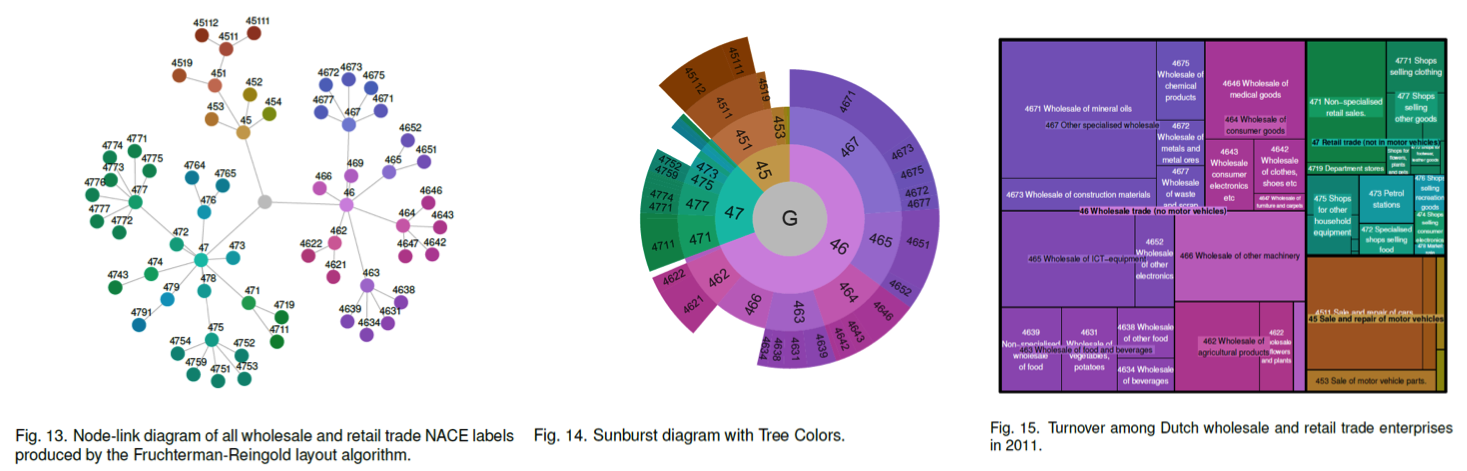
- 通过本文的颜色配色方案来表达经济类别性数据
- 可以通过颜色方案来表达地理信息的方位
User Study:
设计问题比较 Main branch Colors 和 Tree Colors:
- 观察元素之间的相互关系
- 观察节点深度信息
- 认为颜色编码方案对可视分析的作用
- 美观性
- 解释性
- 概述性

本文最后证明 Tree Colors 三个特点:
- 每种颜色都是独一无二
- 颜色可以编码父节点-子节点的父子关系
- 颜色编码分层数据的深度信息
文章提出针对对颜色感知存在缺陷的用户,本文方法的存在局限性
✉️ zjuvis@cad.zju.edu.cn